Machine learning là gì? Có những phương pháp tiếp cận nào? Các thuật toán machine learning phổ biến là gì? Ứng dụng của machine learning ra sao? Tất tần tật những thắc mắc trên sẽ được Vinno giải đáp ngay trong bài viết dưới đây.
Nội dung bài viết
Machine learning là gì?
Machine learning là một lĩnh vực của trí tuệ nhân tạo (AI) tập trung vào việc phát triển các thuật toán và mô hình để giúp máy tính tự động học hỏi từ dữ liệu mà không cần được lập trình trực tiếp.

Thay vì chỉ định rõ từng bước để giải quyết một vấn đề cụ thể, machine learning cho phép máy tính tự động học hỏi từ dữ liệu đầu vào và cải thiện hiệu suất của mình theo thời gian. Machine learning có nhiều ứng dụng trong đời sống và công nghiệp, từ phân tích dữ liệu cho đến tự động hóa quyết định và tối ưu hóa quy trình sản xuất.
Tầm quan trọng của machine learning
Sau khi đã nắm rõ machine learning là gì, bạn sẽ nhận thấy các doanh nghiệp đang ngày càng nhận ra tầm quan trọng của machine learning. Vì nó cho phép họ có cái nhìn sâu sắc hơn về xu hướng và hành vi của khách hàng, cũng như xây dựng mô hình hoạt động kinh doanh và phát triển sản phẩm mới.
Nhiều tập đoàn lớn, chẳng hạn như Facebook, Google và Uber, đã biến học máy thành một phần không thể thiếu trong chiến lược kinh doanh của họ. Thực tế, học máy đang trở thành một yếu tố quan trọng giúp các công ty vượt qua đối thủ cạnh tranh.
Đọc thêm: Top 8 website tốt nhất để bạn tìm hiểu và học machine learning
Các loại machine learning
Có khá nhiều cách phân loại machine learning, trong bài viết này, Vinno sẽ chia machine learning làm 4 loại: học có giám sát (Supervised learning), học không giám sát (Unsupervised learning), học bán giám sát (Semi-supervised learning) và học tăng cường (Reinforcement learning). Tùy vào loại dữ liệu các nhà khoa học muốn dự đoán, họ sẽ chọn sử dụng loại dữ liệu thuật toán phù hợp.
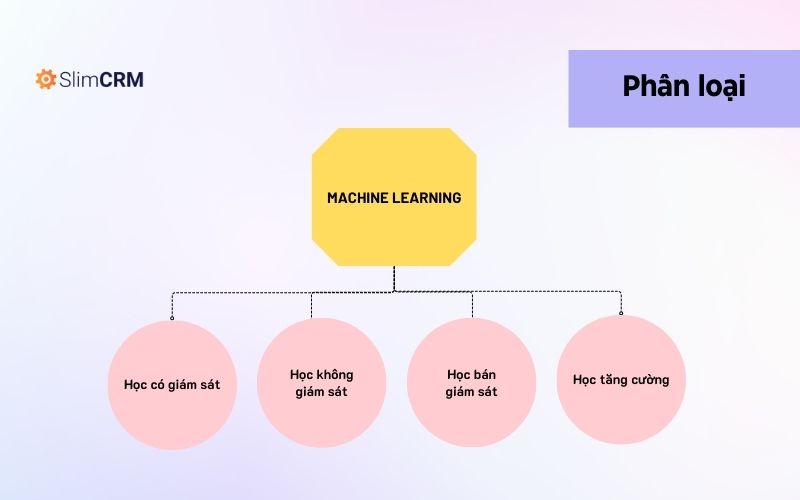
Học có giám sát
Còn được gọi là học có giám sát, phương pháp này sử dụng các bộ dữ liệu được gắn nhãn để huấn luyện các thuật toán phân loại dữ liệu hoặc dự đoán kết quả chính xác. Khi mô hình nhận dữ liệu đầu vào, nó sẽ điều chỉnh trọng số để đạt được độ chính xác mong muốn. Quá trình này thường kết hợp với phương pháp xác thực chéo để đảm bảo rằng mô hình không trang bị thừa hoặc thiếu thông tin.
Học có giám sát có thể giúp các tổ chức giải quyết nhiều vấn đề thực tế, chẳng hạn như phân loại thư rác trong hộp thư đến. Các phương pháp phổ biến của học có giám sát bao gồm mạng thần kinh, bayes ngây thơ, hồi quy tuyến tính, hồi quy logistic, rừng ngẫu nhiên và máy vectơ hỗ trợ (SVM).
Học không giám sát
Còn được gọi là học máy không giám sát, phương pháp này sử dụng các thuật toán học máy để phân tích và phân cụm các bộ dữ liệu không được gắn nhãn. Các thuật toán này có khả năng khám phá các mẫu hoặc nhóm dữ liệu ẩn mà không cần sự can thiệp của con người. Phương pháp này rất hữu ích trong việc phân tích dữ liệu khám phá, chiến lược bán chéo, phân khúc khách hàng và nhận dạng hình ảnh và mẫu bởi khả năng khám phá các điểm tương đồng và khác biệt trong thông tin của chúng.
Nó cũng được sử dụng để giảm số lượng tính năng trong một mô hình thông qua quá trình giảm kích thước, đó là phương pháp phân tích thành phần chính (PCA) và phân tích giá trị đơn lẻ (SVD). Các thuật toán khác được sử dụng trong học không giám sát bao gồm mạng thần kinh, phương pháp phân cụm k-means và phương pháp phân cụm xác suất.
Học bán giám sát
Phương pháp học bán giám sát cung cấp giải pháp kết hợp giữa học có giám sát và không giám sát. Trong quá trình huấn luyện, nó sử dụng tập dữ liệu được gắn nhãn nhỏ hơn để hướng dẫn phân loại và trích xuất tính năng từ tập dữ liệu lớn hơn, không được gắn nhãn. Phương pháp này giải quyết vấn đề thiếu dữ liệu được gắn nhãn cho thuật toán học có giám sát. Nó cũng hữu ích trong trường hợp đánh nhãn đầy đủ dữ liệu quá tốn kém.
Học tăng cường
Học máy tăng cường (Reinforcement Learning) là một phương pháp học máy trong đó một thuật toán được lập trình để học và cải thiện cách hoạt động của một hệ thống thông qua việc tương tác liên tục với môi trường. Thuật toán này học cách chọn hành động tối ưu trong một tình huống cụ thể dựa trên việc nhận phản hồi tích cực hoặc tiêu cực từ môi trường. Mục tiêu của học máy tăng cường là tối đa hoá phần thưởng nhận được từ môi trường thông qua việc tìm kiếm và chọn ra hành động tốt nhất.
Các ứng dụng của học máy tăng cường rất đa dạng, từ các trò chơi điện tử đến các hệ thống tự động lái xe và robot. Nó cũng được sử dụng trong các lĩnh vực như tài chính, quản lý sản xuất và y tế để tối ưu hóa quyết định và tăng cường hiệu suất.
Các thuật toán machine learning phổ biến
Cùng điểm qua top 10 thuật toán machine learning hàng đầu mà bất kỳ người mới bắt đầu nào cũng nên biết ngay dưới đây.
Linear Regression
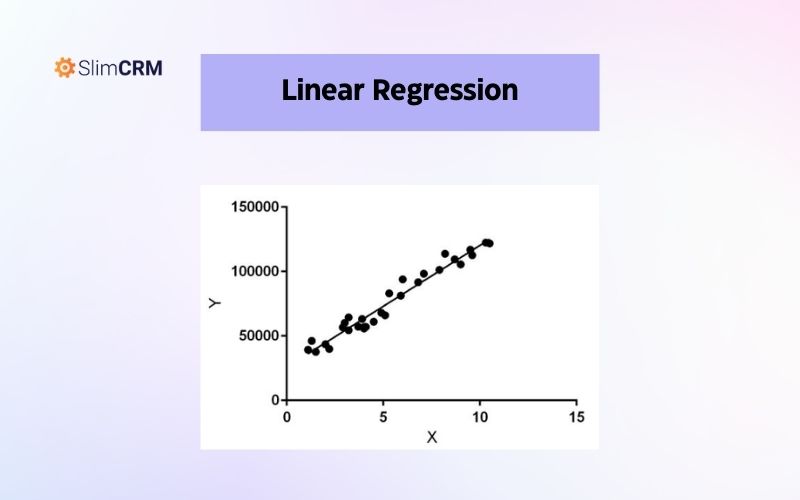
Đây là một thuật toán học máy phổ biến trong việc dự đoán các giá trị liên tục. Thuật toán này xác định mối quan hệ tuyến tính giữa các biến đầu vào và đầu ra bằng cách tìm ra đường thẳng tốt nhất để khớp với dữ liệu. Thuật toán này có thể được sử dụng để dự đoán giá cổ phiếu, giá nhà, hoặc bất kỳ giá trị liên tục nào khác.
Logistic Regression
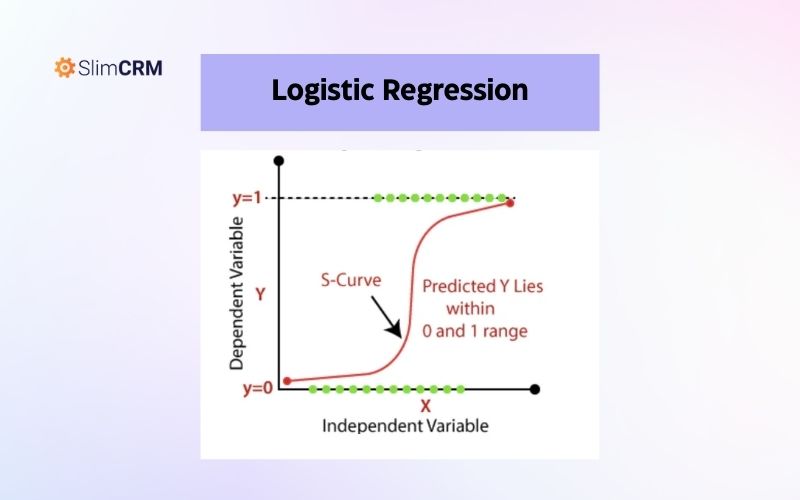
Đây là một thuật toán phân loại được sử dụng để dự đoán xác suất của một sự kiện xảy ra hoặc không xảy ra. Thuật toán này sử dụng hàm logistic để tính toán xác suất và sau đó tạo ra các dự đoán phân loại. Logistic Regression được sử dụng trong các bài toán phân loại như phân loại email là thư rác hay không, hay phân loại khách hàng tiềm năng.
Decision Tree
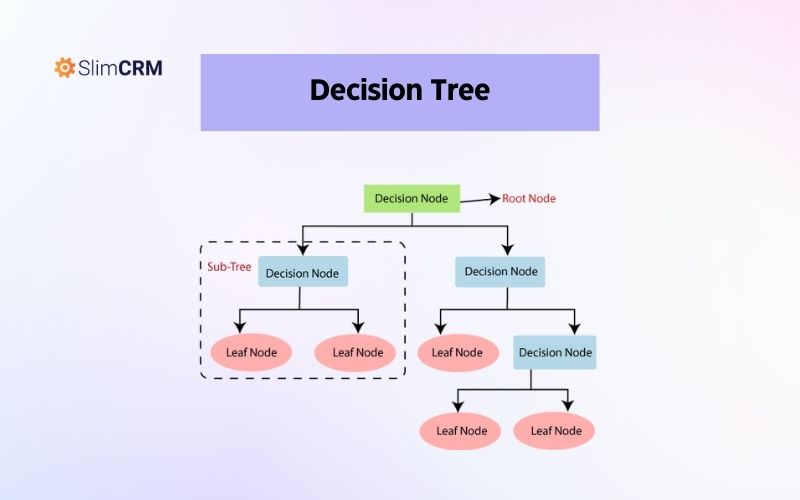
Decision Tree là một thuật toán học máy được sử dụng để dự đoán đầu ra dựa trên các quyết định được đưa ra trên cây quyết định. Thuật toán này tách dữ liệu thành các nhánh dựa trên các câu hỏi và quyết định được đưa ra. Decision Tree được sử dụng để phân loại khách hàng tiềm năng, dự đoán thành công của một sản phẩm mới, hoặc phát hiện bệnh tật.
Random Forest
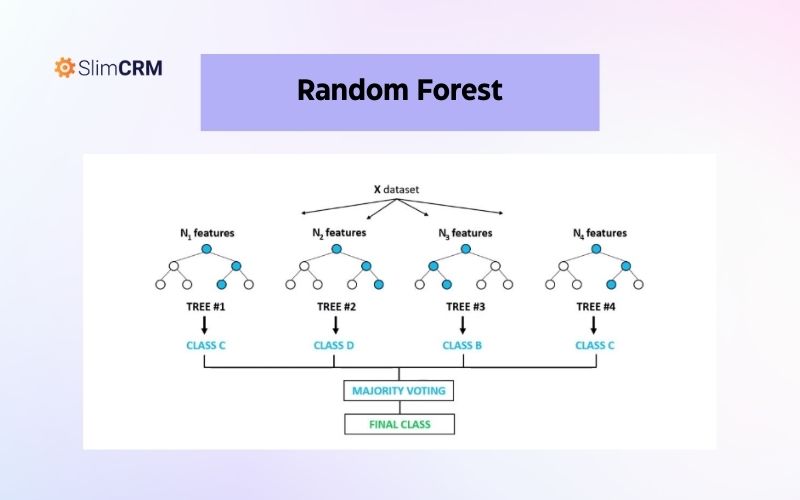
Đây là một thuật toán học máy phân loại và dự đoán được sử dụng cho các tập dữ liệu lớn. Thuật toán này tạo ra nhiều cây quyết định ngẫu nhiên và kết hợp chúng để tạo ra một dự đoán cuối cùng. Random Forest thường được sử dụng để phân loại khách hàng, dự đoán giá cổ phiếu, hoặc dự đoán thành công của một sản phẩm mới.
Naive Bayes
Naive Bayes là một thuật toán phân loại dựa trên lý thuyết xác suất. Thuật toán này tính toán xác suất của một mẫu thuộc về một lớp nhất định và sau đó chọn lớp có xác suất cao nhất làm dự đoán. Naive Bayes được sử dụng trong các bài toán phân loại văn bản, phân loại ảnh, hay phân loại tin tức.
Support Vector Machine (SVM)
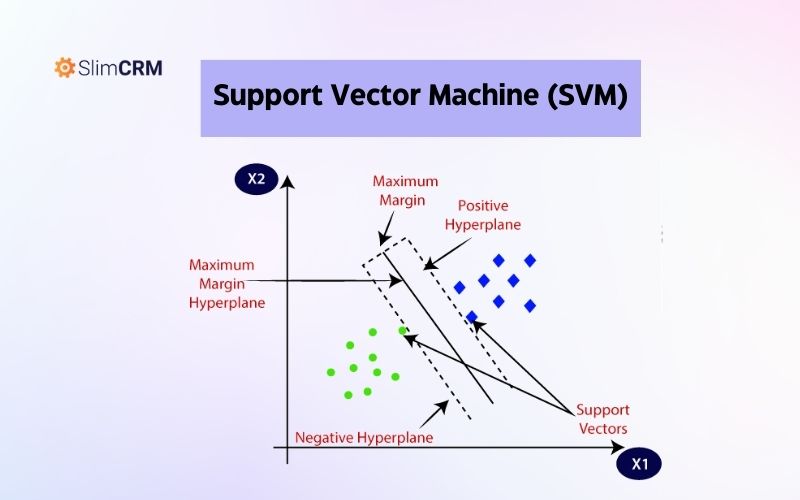
Đây là một thuật toán học máy phân loại và hồi quy được sử dụng để tìm ra đường ranh giới tốt nhất giữa các lớp dữ liệu. Thuật toán này tìm ra đường ranh giới sao cho khoảng cách từ các điểm dữ liệu đến đường ranh giới là lớn nhất. SVM thường được sử dụng trong các bài toán phân loại văn bản, phân loại ảnh, hoặc phân loại khách hàng.
K-Nearest Neighbors (KNN)
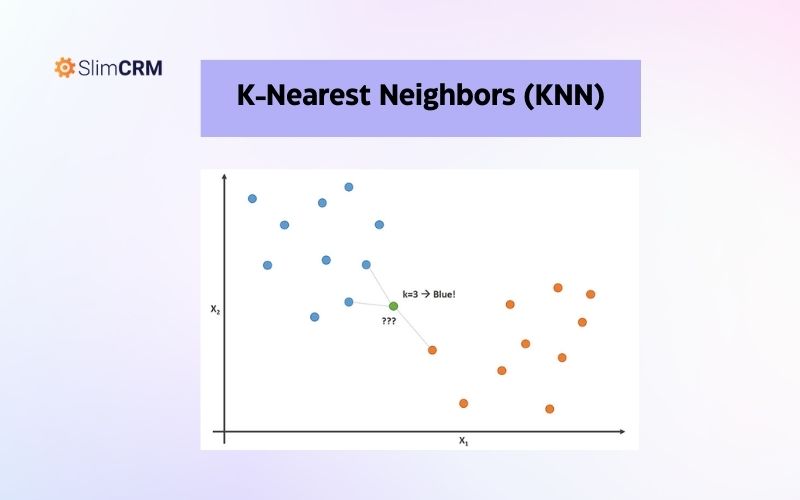
Đây là một thuật toán phân loại và dự đoán sử dụng khoảng cách Euclidean để tìm k điểm dữ liệu gần nhất với một điểm dữ liệu mới. Sau đó, thuật toán sử dụng các nhãncủa các điểm gần nhất để dự đoán nhãn của điểm mới. KNN được sử dụng trong các bài toán phân loại khách hàng, phân loại sản phẩm, hay phân loại ảnh.
Artificial Neural Network (ANN)
ANN là một mạng thần kinh nhân tạo được sử dụng để học mô hình phi tuyến tính và phi tuyến. Thuật toán này được cấu trúc dưới dạng các lớp nơ-ron được kết nối với nhau để tạo ra một mô hình học máy. ANN thường được sử dụng trong các bài toán nhận dạng giọng nói, nhận dạng chữ viết tay, hay nhận dạng khuôn mặt.
Gradient Boosting
Đây là một phương pháp tối ưu hóa học máy được sử dụng để tạo ra một mô hình dự đoán bằng cách kết hợp nhiều mô hình yếu lại với nhau. Thuật toán này tạo ra một mô hình dự đoán bằng cách lặp lại quá trình tối ưu hóa trên các mô hình yếu. Gradient Boosting thường được sử dụng trong các bài toán như dự đoán giá cổ phiếu, hoặc dự đoán thành công của một sản phẩm mới.
Deep Learning
Deep Learning là một lớp các thuật toán học máy sử dụng các mạng thần kinh sâu để giải quyết các vấn đề khó khăn, bao gồm nhận dạng hình ảnh, giọng nói, ngôn ngữ tự nhiên và xử lý ngôn ngữ tự nhiên. Thuật toán này sử dụng các lớp ẩn để học các đặc trưng phân cấp và tạo ra một mô hình dự đoán phức tạp với độ chính xác cao. Deep Learning thường được sử dụng trong các bài toán nhận dạng khuôn mặt, xử lý ngôn ngữ tự nhiên, hay tự động lái xe.
Ứng dụng của machine learning trong chuyển đổi số
Công nghệ học máy (Machine Learning) đã được áp dụng rộng rãi trong nhiều lĩnh vực khác nhau để giải quyết các vấn đề phức tạp và đưa ra các giải pháp hiệu quả. Dưới đây là một số ứng dụng thực tiễn của Machine Learning trong chuyển đổi số:
Tự động hóa quy trình
Machine Learning được sử dụng để xử lý dữ liệu và tạo ra các hệ thống tự động hóa quy trình. Ví dụ, các hệ thống chatbot được sử dụng để giải quyết các câu hỏi của khách hàng và giúp tối ưu hóa quy trình hỗ trợ khách hàng.
Tối ưu hóa sản xuất
Machine Learning được sử dụng để phân tích dữ liệu và tối ưu hóa quy trình sản xuất, giúp giảm chi phí và tăng năng suất sản xuất.
Dự đoán và phân tích dữ liệu
Machine Learning được sử dụng để dự đoán và phân tích dữ liệu phức tạp. Ví dụ, các công ty tài chính sử dụng Machine Learning để dự đoán xu hướng thị trường và đưa ra quyết định đầu tư.
Tư vấn và dự đoán khách hàng
Machine Learning được sử dụng để phân tích hành vi khách hàng và dự đoán các xu hướng tiêu dùng trong tương lai. Ví dụ, các công ty bán lẻ sử dụng Machine Learning để tư vấn sản phẩm và quảng cáo.
Y tế
Machine Learning được sử dụng để phân tích dữ liệu y tế và tạo ra các phương pháp điều trị mới. Ví dụ, các hệ thống tự động chuẩn đoán bệnh được phát triển bằng Machine Learning để cải thiện chính xác và tốc độ chuẩn đoán.
Trên đây là bài viết machine learning là gì và 10 thuật toán machine learning mới nhất cần biết. Hy vọng qua bài viết này, bạn đọc đã hiểu hơn về machine learning, cách phân loại, các thuật toán và ứng dụng của công nghệ này trong chuyển đổi số. Đừng quên theo dõi Vinno để tiếp tục cập nhật những kiến thức hữu ích khác nhé!






